

در دنیای امروز که داده ها هر لحظه تغییر میکنند، نیاز به الگوریتم های گوگل داریم که یاد بگیرند و خودشان را تطبیق دهند. الگوریتم تطبیق عصبی دقیقا همین کار را میکند، مثل یک دوست باهوش که با شرایط جدید هماهنگ میشود. تصور کنید با داده های نامرتب کار میکنید یا الگوریتم های قدیمی عقب میمانند. این الگوریتم با شبکه های عصبی ساده، دقت را بالا میبرد و کارها را آسان تر میکند. برای تشخیص تصویر، صدا یا داده های روزمره عالی است.
در این مقاله، قدم به قدم با این الگوریم آشنا میشوید و تمامی نکات مربوط به Neural Matching را باهم می آموزیم، در پایان مقاله برای شما یک نکته طلایی آوردم که محتواهای شما را با این الگوریتم هماهنگ میکند.
قبل از اینکه به سراغ توضیح تطبیق عصبی گوگل بریم باید با چند مفهموم و تعریف آشنا بشیم:
گوگل در گذشته الگوریتم های خود را نظیر الگوریتم پاندا و الگوریتم پنگوئن ارائه میکرد که همچنان نیز این راه را ادامه میدهد. تطبیق عصبی به گفته متخصصان همانند یک هوش مصنوعی برای مرتبط کردن هرچه بهتر کلمات به مفاهیم قابل درک برای موتور های جستجو میباشد یا به عبارت دیگر، عبارت های جستجو شده به محتوای بالا آمده نزدیک تر است.
مقایسه الگوریتم تطبیق عصبی با روش های سنتی رتبه بندی
در دنیای جستجوگرها، گوگل از مدت ها قبل از الگوریتم هایی مانند پاندا و پنگوئن برای رتبه بندی صفحات استفاده میکرد. این الگوریتم ها عمدتا بر کیفیت محتوا و بک لینک ها تمرکز داشتند. اما الگوریتم تطبیق عصبی (Neural Matching) گامی فراتر از این هاست. این الگوریتم نه تنها کیفیت محتوا را در نظر میگیرد، بلکه ارتباط معنایی بین جملات جستجو شده و محتوای موجود در صفحات وب را به طور دقیق تر بررسی میکند.
الگوریتم تطبیق عصبی چیست؟
به زبان ساده؛ تطبیق عصبی بیشتر به این مسئله میپردازد که چگونه موتور جستجو معنای دقیق تری از کلمات جستجو شده را درک کند و از آن برای شناسایی محتوای مرتبط تر استفاده نماید. به عبارت دیگر، این الگوریتم سعی دارد جستجوهای پیچیده تر و معنایی تر را با دقت بیشتری پوشش دهد و از این نظر یک پیشرفت عمده در راستای بهبود تجربه جستجو است.
Neural Matching Algorithms دسته ای از روش های پیشرفته مبتنی بر شبکه های عصبی هستند که برای مقایسه و تطبیق داده های پیچیده (مانند متن، تصویر، صدا یا حتی گراف ها) استفاده میشوند. این الگوریتم ها با یادگیری خودکار ویژگی های معنایی و ساختاری داده ها، دقت تطبیق را به طور چشمگیری افزایش میدهند.
برخلاف روش های سنتی مبتنی بر قوانین یا شباهت ساده (مثل Levenshtein Distance)، الگوریتم های عصبی تطبیق معنایی (Semantic Matching) را فراهم میکنند. این الگوریتم ها در حوزه هایی مانند جستجوی هوشمند، توصیه گرها، تشخیص تقلب، پردازش زبان طبیعی (NLP) و بینایی کامپیوتر کاربرد دارند.
مقایسه الگوریتم تطبیق عصبی و رنک برین
الگوریتم های تطبیق عصبی و رنک برین هر دو در راستای درک بهتر جستجوهای معنایی طراحی شده اند، اما رویکردهای متفاوتی دارند. رنک برین بیشتر به درک نیت جستجو و تحلیل معنای جملات پیچیده میپردازد، در حالی که تطبیق عصبی تمرکز بیشتری بر تطبیق کلمات با مفاهیم دارد تا محتوای مرتبط تری را پیدا کند.
ویژگی رنک برین تطبیق عصبی
- هدف اصلی درک نیت جستجو و معنا از طریق یادگیری ماشینی تطبیق کلمات جستجو شده با مفاهیم در صفحات وب
- تکنولوژی استفاده شده یادگیری ماشینی و پردازش زبان طبیعی الگوریتم های عصبی برای درک بهتر مفاهیم
- تمرکز اصلی شناسایی معنای دقیق تر و نیت جستجو ارتباط میان کلمات جستجو شده و محتوای مرتبط تر
- کاربرد جستجوهای پیچیده و معنایی تر شناسایی ارتباطات میان کلمات و مفاهیم
نحوه کار الگوریتم تطبیق عصبی گوگل
الگوریتم تطبیق عصبی یکی از روش های هوش مصنوعی است که به کمک شبکه های عصبی عمیق کار میکند. حالا بیاید این مراحل رو به زبان ساده تر توضیح بدیم:
1) استخراج ویژگی ها (Feature Extraction): در این مرحله، از مدل های از پیش آموزش دیده مثل BERT یا GPT برای تبدیل اطلاعات خام (مثل متن یا تصویر) به بردارهای عددی استفاده میشود. این بردارها چیزی شبیه به فهرستی از اعداد هستند که به مدل کمک میکنند تا محتوای داده ها رو بهتر درک کنه.
مثال: وقتی میگوییم “سیب قرمز”، سیستم این عبارت رو به یک سری اعداد تبدیل میکند مثل [0.2, -0.1, 0.5,…] تا بتونه اطلاعات رو پردازش کنه.
2) محاسبه شباهت (Similarity Computation): بعد از اینکه داده ها به بردار تبدیل شدند، حالا باید مقایسه بشن تا ببینیم چقدر شبیه به هم هستند. این کار با استفاده از فرمول هایی مثل Cosine Similarity انجام میشه که مقایسه میکنه بردارهای مختلف چقدر شبیه هم هستند. اگر دو بردار شبیه هم باشند، یعنی اطلاعاتشون شبیه به هم هست.
یک مثال ساده: Cosine Similarity میگه که چقدر زاویه بین دو بردار شبیه به هم است.
3) یادگیری تطبیقی (Adaptive Learning): در این مرحله، الگوریتم یاد میگیره که چه داده هایی به هم شبیه هستن و چه داده هایی نیستن. مثلا اگر دو جمله مثل “سیب قرمز” و “سیب سبز” رو بهش بدیم، به مدل گفته میشه که این ها شبیه هم هستن. اما اگه “سیب قرمز” رو با “خانه سبز” مقایسه کنیم، مدل یاد میگیره که این ها شبیه هم نیستن. برای آموزش مدل از چیزی به نام Contrastive Loss استفاده میشه که به مدل کمک میکنه تا فاصله بین بردارهای شبیه و غیرشبیه رو کم کنه.
4) بهینه سازی (Optimization): در این مرحله، مدل سعی میکنه که عملکردش رو بهتر کنه. این کار معمولا با استفاده از الگوریتم هایی مثل Gradient Descent انجام میشه. این الگوریتم به مدل کمک میکنه که بتونه خطاهای خودش رو کاهش بده و بهتر بشه.
بطور خلاصه، این الگوریتم با تبدیل داده ها به بردارهای عددی، شباهت ها رو محاسبه کرده و به کمک آموزش، یاد میگیره که چه داده هایی به هم شبیه هستن و چه داده هایی نیستن. در نهایت با تکنیک هایی مثل بهینه سازی، مدل رو بهتر میکنیم.
مقایسه Ad-hoc Retrieval با الگوریتم تطبیق عصبی در رتبه بندی صفحات وب
Ad-hoc retrieval یکی از روش های رتبه بندی است که به طور مشابه با تطبیق عصبی، به محتوای صفحات توجه دارد. در این سیستم، رتبه بندی صفحات وب به جای استفاده از بک لینک ها و عوامل سنتی، بر اساس محتوا و ارتباط معنایی با عبارت های جستجو انجام میشود. هرچند Ad-hoc retrieval شباهت هایی به تطبیق عصبی دارد، اما الگوریتم تطبیق عصبی به طور هوشمندانه تری مفهوم عبارت های جستجو شده را با محتوای صفحات مرتبط میکند.
مزایا و چالش ها
بیاید باهم مزایا و چالش های این الگوریتم را بررسی کنیم:
مزایا
- دقت بالا: تطبیق معنایی حتی با تفاوت های ظاهری (مثل مترادف ها).
- انعطاف پذیری: کار با داده های ناهمگن.
- یادگیری بدون نظارت: با مدل های از پیش آموزش دیده.
چالش ها
هزینه محاسباتی: نیاز به GPU برای داده های بزرگ.
داده های آموزشی: نیاز به جفت های باکیفیت.
کاربردهای عملی
- Google Search: تطبیق query با صفحات.
- Spotify: تطبیق آهنگ ها بر اساس صدا.
- eBay: تطبیق محصولات مشابه.
- پزشکی: تطبیق تصاویر MRI.

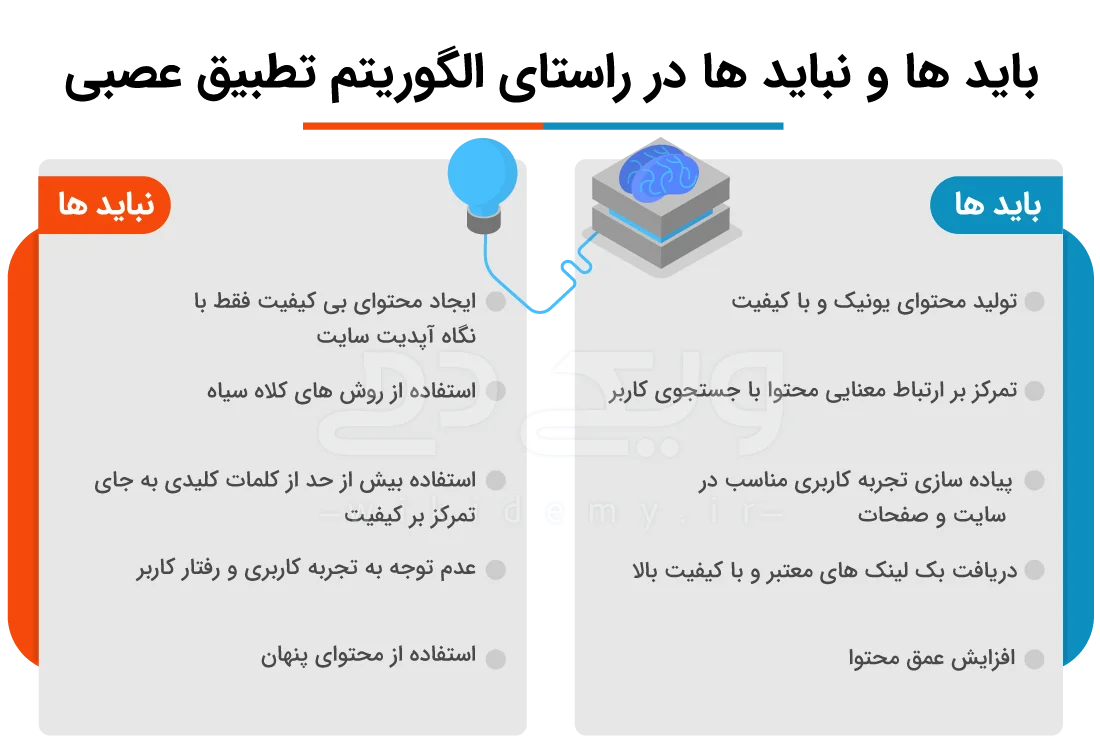
نبایدها الگوریتم تطبیق عصبی
- استفاده از محتوای بی کیفیت: محتوای بی ارزش و غیرمرتبط با جستجو میتواند رتبه شما را پایین می اورد.
- دستکاری نتایج جستجو: دستکاری نتایج با روش های کلاه سیاه، مانند پر کردن کلمات کلیدی، مجاز نیست.
- تمرکز روی کلمات کلیدی: استفاده بیش از حد از کلمات کلیدی باعث غیرطبیعی شدن محتوا میشود.
- محتوای تکراری: ایجاد محتوای مشابه باعث کاهش کیفیت و رتبه در جستجو میشود.
- نادیده گرفتن تجربه کاربری: محتوای بی کیفیت و تجربه ضعیف کاربری رتبه شما را تحت تاثیر قرار میدهد.
- پنهان کردن محتوا: محتوای مخفی یا نادرست برای موتور جستجو قابل شناسایی است و به ضرر شماست.
بایدهای الگوریتم تطبیق عصبی
- تولید محتوای منحصر به فرد: محتوای با کیفیت و خاص باعث بهبود رتبه شما میشود.
- تمرکز بر ارتباط معنایی: باید محتوای شما مرتبط با جستجوی کاربر باشد، نه فقط کلمات کلیدی.
- ارتقا تجربه کاربری: طراحی و تجربه خوب برای کاربران باعث ارتقا رتبه در جستجو میشود.
- استفاده از لینک های معتبر: لینک های با کیفیت و معتبر به افزایش اعتبار صفحه کمک میکند.
- توجه به مقیاس پذیری محتوا: ایجاد محتوای عمیق و جامع به جذب مخاطب و بهبود رتبه کمک میکند.
نکته طلایی
نتیجه گیری
الگوریتم تطبیق عصبی نه تنها چالش های داده های پویا را حل میکند، بلکه آینده هوش مصنوعی را شکل میدهد. با یادگیری مداوم و تطبیق سریع، دقت را افزایش میدهد و هزینه ها را کاهش میدهد، دقیقا آنچه برای کاربردهای واقعی مانند تشخیص تصویر، پردازش زبان و تحلیل داده نیاز دارید.
این الگوریتم با یادگیری پویا و تطبیق خودکار، نه تنها دقت را بهبود میبخشد، بلکه هزینه ها را نیز به طور چشمگیری کاهش میدهد. این ویژگی ها آن را به ابزاری ضروری برای کاربردهایی چون پردازش زبان، تحلیل داده های بزرگ و تشخیص تصویر تبدیل کرده است.
درصورت داشتن سوال یا بودن ابهام در مقاله در کامنت ها برام بنویسید؛ خیلی سریع به سوالات شما پاسخ میدهیم “ارادتمند شما ویکی دمی”



دیدگاه شما